
Anthropic Releases Claude Fable 5 and Mythos 5: A Breakthrough in Autonomous AI
On this page
It’s official: on June 9, 2026, Anthropic released Claude Fable 5 to the public — the most powerful artificial intelligence model in the company’s history. At the same time, its “older” version, Claude Mythos 5, was launched but with severe restrictions: it is available only to intelligence agencies and companies working with critical infrastructure. Both models are detailed in an article on the company’s website.

This is not a routine update. The previous version of this AI — Claude Mythos Preview — was released by Anthropic back in April, but the company immediately blocked broad access to it. The reason was stated openly: the model proved so powerful in the field of cybersecurity that it could help malicious actors break into systems — and this genuinely frightened the developers themselves. Two months were spent creating safety mechanisms robust enough for a public release.
Two Faces of the Same Model
Fable 5 and Mythos 5 are essentially the same neural network with identical capabilities. The difference is that Fable 5 comes equipped with a filtering system that intercepts potentially dangerous requests. When such a request is detected, instead of Fable 5, the previous model — Claude Opus 4.8 — provides the response. The user sees a notification about the switch.
According to Anthropic, this happens in less than 5% of cases — meaning that during routine work, most people will not encounter such a “swap” at all.
Mythos 5, unlike Fable 5, operates without these restrictions. But it is unavailable to the general public — accessible only to vetted organizations through a special program called Project Glasswing, run jointly with the U.S. government.
Mythos 5 and Cybersecurity: A Double-Edged Sword
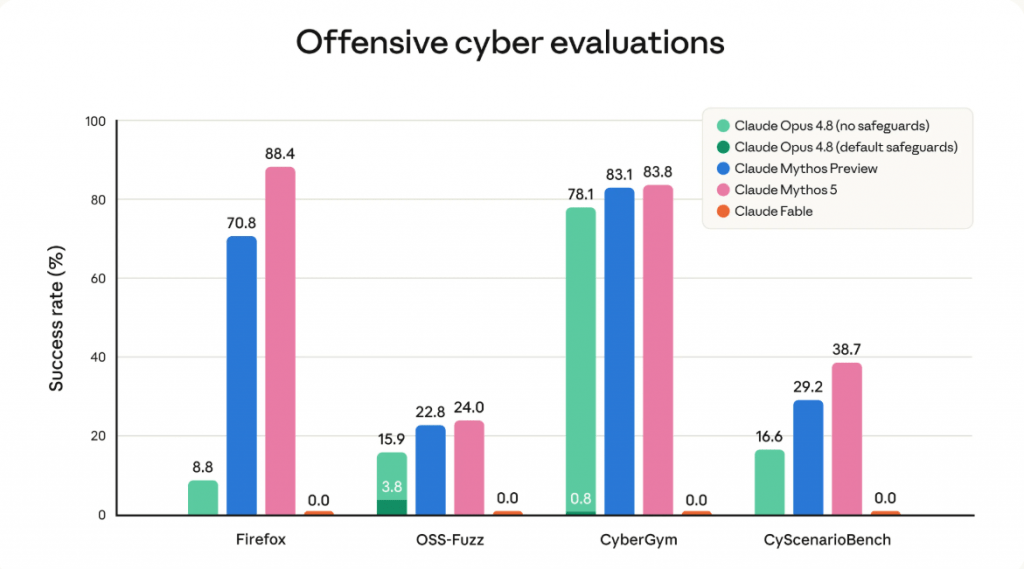
Mythos 5 achieved the world’s best results in cybersecurity — which is precisely why the company refused to release it to the public. At first glance, this seems strange: shouldn’t a powerful defensive tool be open to everyone?
Source: Anthropic
The paradox is that cybersecurity is a dual-use domain. The very skills that make the model useful for defenders can turn it into a weapon for attackers. Mythos 5 can autonomously find vulnerabilities in software, chain attacks together, and automatically recover from failures — doing exactly what used to require a team of expert hackers, expensive tools, and weeks of work. Now that takes hours and costs mere pennies.
- Example: During internal testing, Mythos Preview autonomously discovered and chained together 271 zero-day vulnerabilities in the Firefox browser. These were real, previously unknown holes that could be used for hacking.
It was this result that frightened Anthropic’s engineers and prompted management to immediately block broad access to the model.
In other words, Mythos 5 does not merely “know about hacking” — it can perform hacking autonomously and at industrial scale. For a cybersecurity specialist, it would allow finding and closing vulnerabilities in a single day that might otherwise go unnoticed for years. But in the hands of a malicious actor, it means the ability to attack infrastructure with unprecedented speed and efficiency. One and the same tool — opposite consequences.
Fable 5 as an AI Agent: Long-Haul Autonomous Work
 Source: Anthropic
Source: Anthropic
The main thing that sets Fable 5 apart from everything that came before is its ability to work autonomously on complex tasks for hours and weeks without losing context. Previous models handled short queries well but faltered on long, multi-step assignments. Fable 5 not only maintains focus — it takes intermediate notes as it works and checks its own results before declaring a task complete.
- A striking example is the test with Stripe. A team of programmers would have needed more than two months to manually update a 50-million-line codebase. Fable 5 did it in one day.
- Another telling case is the game Pokémon FireRed. Previous versions of Claude could only complete it with a set of auxiliary tools — maps, hints, extra data. Fable 5 finished the game entirely, relying only on ordinary screen captures — just as a human player would. https://www.youtube.com/watch?v=Ty_50J84fMY
Source: Anthropic
Numbers and Benchmarks: How Fable 5 Stacks Up Against Competitors
Source: Anthropic
The model leads in nearly all standard tests. Here are the key numbers:
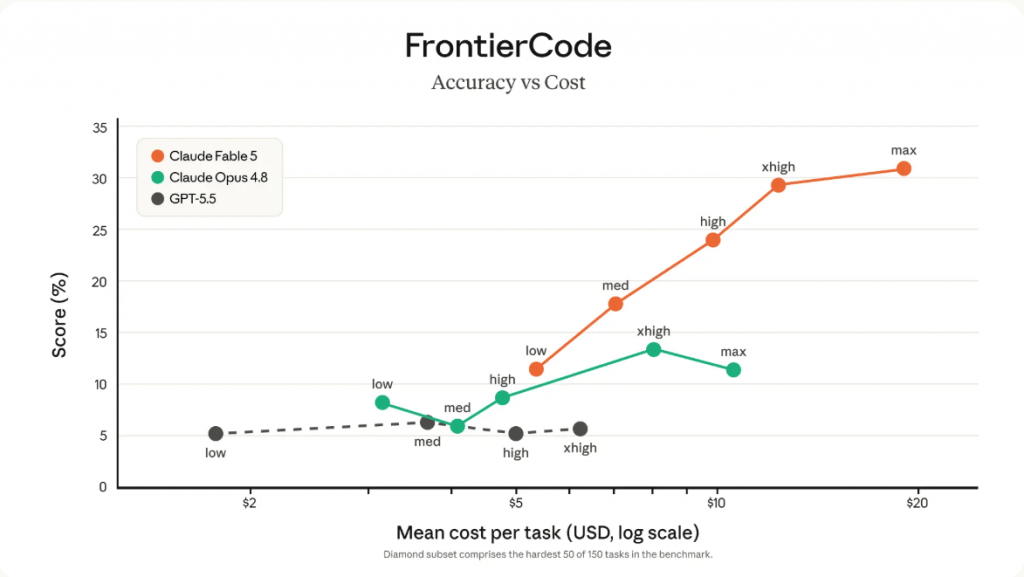
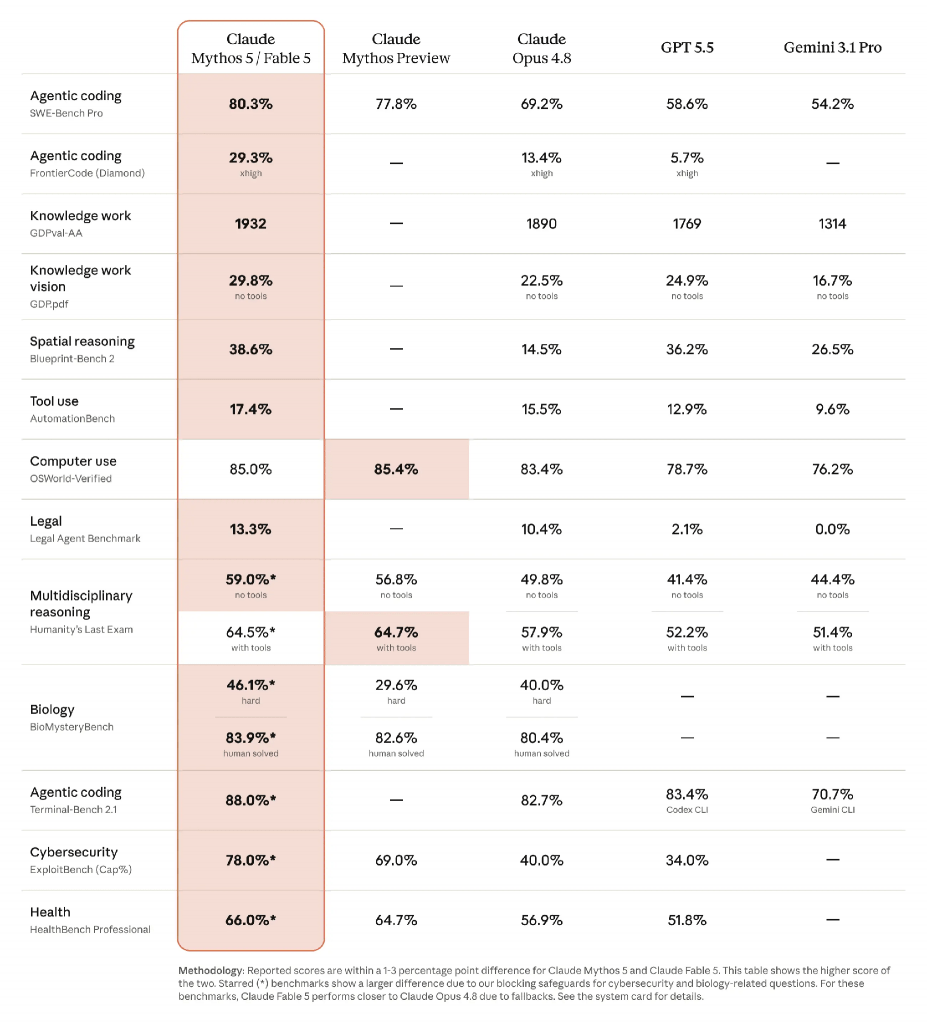
On the programming test (SWE-Bench Pro, real-world GitHub tasks), Fable 5 solved 80% of the problems. For comparison:
- Opus 4.8 (previous best Anthropic model) — 69%,
- GPT-5.5 from OpenAI — 59%,
- Gemini 3.1 Pro from Google — 54%.
On the more difficult code quality test (FrontierCode Diamond), the gap is even larger:
- Fable 5 — 29%,
- Opus 4.8 — 13%,
- GPT-5.5 — only 6%.
Applied tests also show interesting results.
- Business. In analytics, the model became the first to cross the 90% mark on the Hex Analytics benchmark, which tests the ability to handle long and complex business tasks.
- Finance. On the test for senior financial analysts (Hebbia Finance Benchmark), Fable 5 achieved the best result among all models tested. IMC, a trading firm, reported that Fable 5 flawlessly handled their internal data analysis tests — including factual queries, root cause analysis, and expected value calculations.
- Science. Physics researchers note that the model reached in 36 hours what took GPT-5.5 four days to accomplish.
The pattern is clear: the longer and more complex the task, the greater Fable 5’s advantage.
More on Practical Applications of Fable 5
The company demonstrated several impressive examples of what Fable 5 does autonomously:
- Generation and simulation. The model built a simulation of the Solar System — calculating planetary motion from first principles using physics and using it to predict solar eclipses. In another test, it autonomously built an automated factory in the Factorio simulator. In a third, it wrote code to animate fluid in time with music — and generated the music itself. https://www.youtube.com/watch?v=5f5JYLZHdhw
Source: Anthropic
- Drug discovery. In medical research, Mythos 5 accelerated drug discovery roughly tenfold. In one experiment, the model — without human intervention — selected protein binding sites, ran analysis tools, and corrected errors just as a scientist would. Of 14 proteins studied, 9 yielded promising drug candidates that are now being investigated further.
- Genetics research. In genomics, Mythos 5 conducted a fully autonomous study: more than a week of independent work, data on millions of cells from 138 animal species, a model built from scratch that outperformed results published in Science — while being 100 times smaller. Anthropic promises to publish these findings.
Pricing: Power Becomes More Affordable
Fable 5 and Mythos 5 cost $10 per million input tokens and $50 per million output tokens — less than half the price of the previous Mythos Preview. Subscribers to Claude’s paid plans (Pro, Max, Team, Enterprise) can use the model for free from June 9 to June 22, 2026.
To put the scale in perspective: the cost has roughly doubled compared to Opus 4.8. But if Fable 5 in one pass accomplishes what takes Opus 4.8 five attempts, the net expense ends up lower. That is precisely how companies that have already switched to the new model are thinking about it.
Early Adopters: User Feedback
Several companies received early access and shared their impressions:
- Cursor (AI code editor): “The best model on our internal test. It unlocks tasks that were previously out of reach.”
- GitHub: “A significant step forward in autonomy — the model tackles complex, long-horizon tasks with a level of reliability we haven’t seen before.”
- Replit: “The best results of any Claude model we’ve tested.”
- Harvey (legal AI): “In blind comparisons, our lawyers rated Fable 5’s edits as comparable to or better than our current model — every time.”
- Hex (analytics): “The first model to cross 90% on our main benchmark — a 10-point jump over Opus.”
What the Model Will Not Do — And Why That Matters
Special attention is due to how exactly Anthropic restricts Fable 5’s capabilities.
The traditional approach used by most developers is to hardcode the model’s refusal to execute dangerous requests. Anthropic chose a different path: pre-filtering.
The filtering system operates on top of the model in real time and intercepts undesirable requests before Fable 5 answers them.
The filters are intentionally set to be strict, which leads to glitches: sometimes they trigger on perfectly harmless technical questions in cybersecurity or biology. Anthropic openly acknowledges this flaw and promises to reduce such false positives with future updates.
The Bottom Line
Fable 5 is the first case in Anthropic’s history where the company opens up to the general public capabilities that previously required special clearance. The model can work autonomously for hours and weeks, handles tasks that used to demand a team of specialists, and does so at a lower cost than the previous generation. At the same time, the company is building a safety infrastructure that allows for releasing ever more powerful systems without turning them into tools for malicious actors.
We will continue to follow developments. Announced for the near future: further improvements to the filters, expanded access to Mythos 5, and new models that Anthropic promises in the coming months.


